
Applied AI & Compilers @ MPS Lab
Systems & Compilers
- HELM: Heterogeneous Execution of Language Models — Compiler-guided parallelism for low-latency LLM inference on heterogeneous GPU systems via cost-modeling.
- fast_llm — Performance analysis and optimization of LLM inference via custom kernels and compiler optimizations.
- AIKernels — High-performance custom kernels for AI workloads using CUDA and Triton.
Applied AI
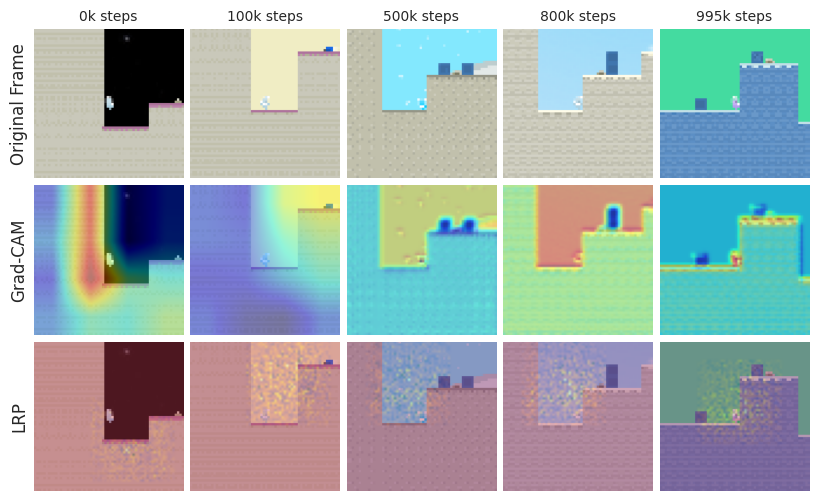
Interpretable Learning Dynamics in Unsupervised Reinforcement Learning
arXiv: 2505.06279
We present an interpretability framework for unsupervised reinforcement learning (URL) agents, aimed at understanding how intrinsic motivation shapes attention, behavior, and representation learning. Our findings show that curiosity-driven agents display broader, more dynamic attention and exploratory behavior than their extrinsically motivated counterparts.
Projects
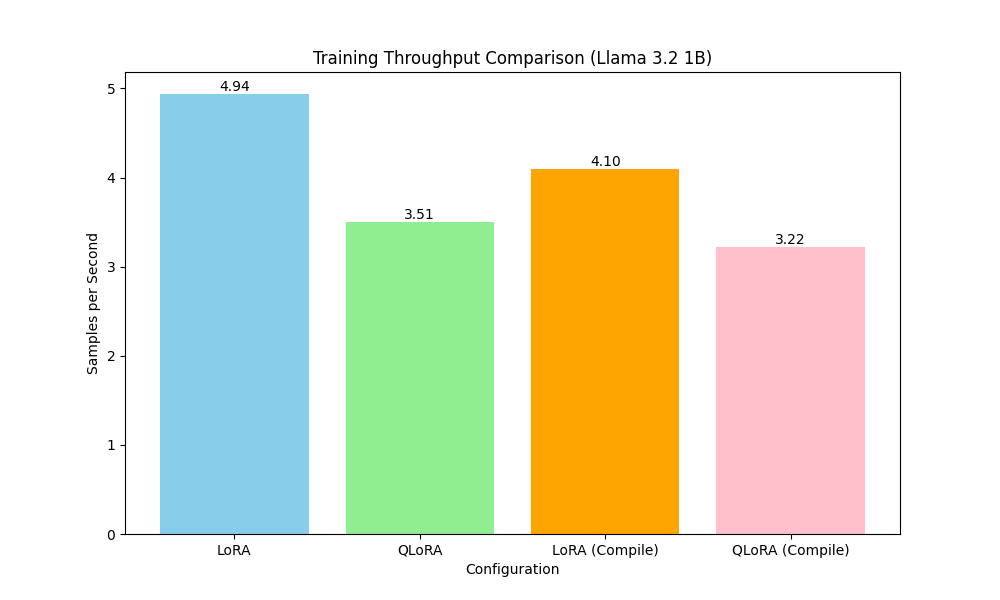
Llama 3.2 Fine-tuning
Fine-tune Llama 3.2 1B on consumer hardware using uv. Includes rigorous benchmarking of training throughput and memory footprint.
Unsupervised RL Interpretability
A comprehensive interpretability framework for understanding how curiosity-driven agents explore and represent the world in unsupervised RL settings.

NanoMamba
Minimal implementation of the Mamba state space model.
Data Engineering Stuff

Experience

• Conducting research on efficient LLM Inference, focusing on kernel performance, memory hierarchy behavior, and runtime scheduling.
• Implemented compiler-level optimizations using LLVM/MLIR, targeting operation fusion, layout transformations, and reduced memory movement.
• Explored distributed/heterogeneous execution strategies to accelerate large-model inference across multi-GPU setups.
• Served as a TA for Advanced Computer Architecture course, topics including pipelining, out-of-order scheduling, cache coherence, memory hierarchy, and GPU programming fundamentals.
• Designed and graded projects involving CPU/GPU performance analysis, instruction-level parallelism, and architectural trade-off evaluation.
• Held weekly office hours guiding students through performance bottlenecks, microarchitectural behavior, and low-level optimization strategies.
• Designed and built near real-time data pipelines from scratch, enabling ad performance insights across Facebook and Google.
• Refactored legacy architecture with multithreading, improving pipeline runtime by ~85% and cutting external API calls by 84%.
• Migrated Zocket's data infrastructure from AWS to GCP, deploying self-managed Spark and Airflow for better control and cost efficiency.
• Developed and managed 50+ production-grade ETL pipelines using AWS Glue, supporting analytics across multiple business functions.
• Improved data quality by 40% through automated validation and Infrastructure-as-Code using AWS CDK.
• Optimized S3 storage and pipeline design for faster, more reliable data processing.